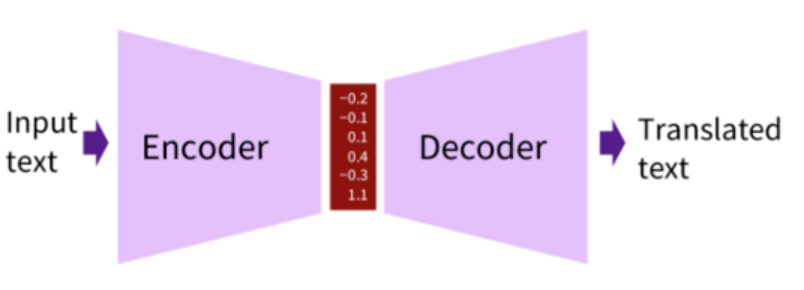
encoder-decoder模型也被叫做序列到序列的学习模型(Sequence to Sequence,Seq2Seq),当然,实际上,它并不是一种具体的模型在实现形式上,更像是一种框架,一种方式。而Encoder和Decoder部分可以是任意的文字,信号,图像,视频数据。所以seq2seq的实现和应用也是非常多样的,例如cnn-rnn实现image caption的应用,lstm-lstm实现nmt翻译的应用。
# 生成一序列的数据 defrandom_sum_pairs(n_examples, n_numbers, largest): X, y = list(), list() for i inrange(n_examples): in_pattern = [randint(1, largest) for _ inrange(n_numbers)] out_pattern = sum(in_pattern) X.append(in_pattern) y.append(out_pattern) return X, y
# 将数据转换为字符串 defto_string(X, y, n_numbers, largest): max_length = n_numbers * math.ceil(math.log10(largest+1)) + n_numbers - 1 Xstr = list() for pattern in X: strp = '+' .join([str(n) for n in pattern]) strp = ''.join([' 'for _ inrange(max_length-len(strp))]) + strp Xstr.append(strp) max_length = math.ceil(math.log10(n_numbers * (largest+1))) ystr = list()
for pattern in y: strp = str(pattern) strp = ''.join([' 'for _ inrange(max_length-len(strp))]) + strp ystr.append(strp) return Xstr, ystr
# 切割字符串 definteger_encode(X, y, alphabet): char_to_int = dict((c, i) for i, c inenumerate(alphabet)) Xenc = list() for pattern in X: integer_encoded = [char_to_int[char] for char in pattern] Xenc.append(integer_encoded)
yenc = list() for pattern in y: integer_encoded = [char_to_int[char] for char in pattern] yenc.append(integer_encoded) return Xenc, yenc
# 将字符串转换为one hot编码 defone_hot_encode(X, y, max_int): Xenc = list() for seq in X: pattern = list() for index in seq: vector = [0for _ inrange(max_int)] vector[index] = 1 pattern.append(vector) Xenc.append(pattern)
yenc = list() for seq in y: pattern = list() for index in seq: vector = [0for _ inrange(max_int)] vector[index] = 1 pattern.append(vector) yenc.append(pattern)
return Xenc, yenc
# 生成数据 defgenerate_data(n_samples, n_numbers, largest, alphabet): X, y = random_sum_pairs(n_samples, n_numbers, largest) X, y = to_string(X, y, n_numbers, largest) X, y = integer_encode(X, y, alphabet) X, y = one_hot_encode(X, y, len(alphabet)) X, y = np.array(X), np.array(y) return X, y
# 数据解码 definvert(seq, alphabet): int_to_char = dict((i, c) for i, c inenumerate(alphabet)) strings = list() for pattern in seq: string = int_to_char[np.argmax(pattern)] strings.append(string) return''.join(strings).lstrip('0')
文章中代码来源[机器之心](https://www.jiqizhixin.com/articles/2019-02-18-13) Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014. [Sequence to Sequence Learning with Neural Networks, 2014. https://arxiv.org/abs/1409.3215 Show and Tell: A Neural Image Caption Generator, 2014. Learning to Execute, 2015. {A Neural Conversational Model, 2015.](https://arxiv.org/abs/1506.05869)